Matrix Formats and Input/Output¶
Clustergrammer takes as input either:
- a tab-separated matrix file
- a Pandas DataFrame (using Clustergrammer-PY)
The tab-separated matrix file can take several formats shown below, which can include row/column categories and name/category titles. In all cases, row and column names must be unique (if input names are not unique then unique integers will be appended to names). Users are encouraged to arrange their matrix with data-points as columns and dimensions as rows, which enables users to take advantage of Clustergrammer’s Interactive Dimensionality Reduction.
The front-end Clustergrammer-JS library can visualize matrices up to ~500,000 to ~1,000,000 cells in size and is also optimized to visualize matrices with more rows than columns – this has been done to accommodate datasets with many dimensions (rows) and few measurements (columns) that are common in biology. However very large matrices may take a long time to cluster using the Clustergrammer-PY library.
Simple Matrix Format¶
The simplest tab-separated file format is shown here:
Col-A Col-B Col-C
Row-A 0.0 -0.1 1.0
Row-B 3.0 0.0 8.0
Row-C 0.2 0.1 2.5
The first row gives the column names and starts with a blank tab. All other rows start with the row name followed by the row data. Row and column titles can be added by prefixing each row or column name with 'Title: ' (not shown in this example). See example_tsv.txt for an example of this matrix format.
Simple-Category Matrix Format¶
Row and column categories can be included in two ways. The first, simple-category format, is shown below:
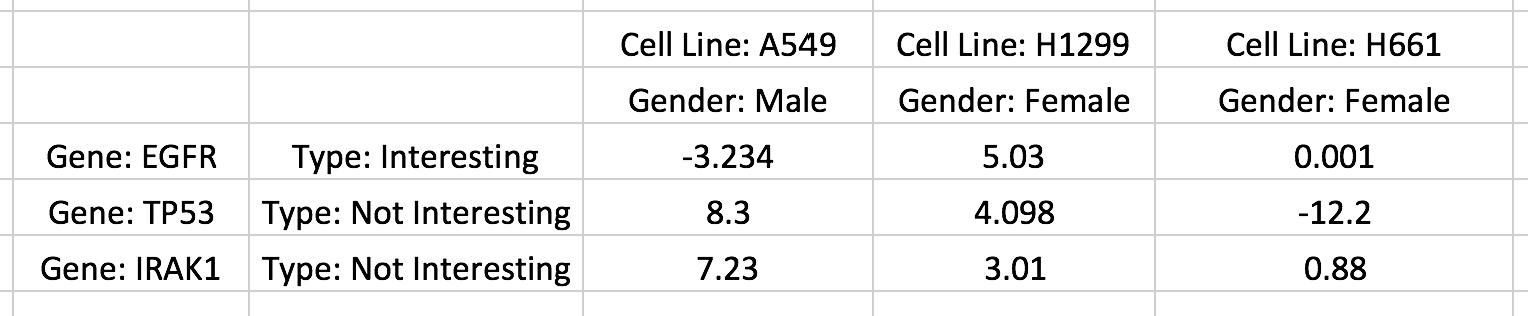
A matrix with row and column categories in ‘simple’ format.
This simple-category format allows users to encode column categories as extra rows underneath column labels and row categories as an extra columns next to row labels. The above screenshot of an Excel spreadsheet shows a single row category being added as an additional column of strings (e.g. Type: Interesting) and a single column category being added as an additional row of strings (e.g. Gender: Male). Up to 15 categories can be added in a similar manner. Titles for row or column names or categories can be added by prefixing each string with 'Title: ' (note the space after the colon). For example, the title of the column names is Cell Line and the title of the row categories is Gender. See rc_two_cats.txt for an example of this matrix format. Titles, if given, will be shown as labels above row/column names or adjacent to row/column categories.
Tuple-Category Matrix Format¶
Row/column names and categories can also be encoded as Python tuples as shown below:
('Cell Line: A549', 'Gender: Male') ('Cell Line: H1299', 'Gender: Female') ('Cell Line: H661', 'Gender: Female')
('Gene: EGFR','Type: Interesting') -3.234 5.03 0.001
('Gene: TP53','Type: Not Interesting') 8.3 4.098 -12.2
('Gene: IRAK','Type: Not Interesting') 7.23 3.01 0.88
The tuple-category format is easier to work with in Python and can be imported/exported into Pandas DataFrames and as tab-separated files. Note that titles have been added to row/column names and categories as discussed above. See tuple_cats.txt for an example of this matrix format.
Category Types: String and Value¶
Row and column categories can be of type: string or value. If categories are given as strings (e.g. containing letters), then categories will be depicted using colors. If categories are of type value (e.g. all categories contain only numbers), then value-categories will be depicted using color and opacity (gray for positive and orange for negative).
Value-based categories can be useful for adding data to your visualization (e.g. drug-dosage value) that you would like to compare to your other dimensions, but that should not influence your clustering. Both value and string categories can also be used to reorder your matrix by double-clicking their labels (see Interactive Categories).
Matrix File Examples¶
Several example tab-separated matrix files can be found in example matrix files.
Matrix Input/Output to Clustergrammer.py¶
Clustergrammer-PY can load a matrix directly from a file or from a Pandas DataFrame as well as export to a file or Pandas DataFrame (for more information see Clustergrammer-PY API):
# initialize Network object
from clustergrammer import Network
net = Network()
# load matrix from file or DataFrame
####################################
# load data from file
net.load_file('your_matrix.txt')
# load data from DataFrame, df
net.load_df(df)
# export matrix
###############
# write matrix to tab separated file
net.write_matrix_to_tsv(filename)
# export data to Pandas DataFrame
df_export = net.export_df()